Bloom filters
Hanif Adedotun ·
“Is this username taken?” — A query asked billions of times a day. Here’s an algorithm that answers that in milliseconds.
The Problem
You’re building the next big social platform. At sign-up, users pick a username. Before hitting the database, you want to check: does this username already exist?
At 10 million users, a naive database lookup is fine. At 500 million users, every single sign-up attempt becomes an expensive query. You need something faster. A Bloom filter does this efficiently.
What Is a Bloom Filter?
A Bloom filter is a space-efficient, probabilistic data structure that answers one question: “Have I seen this element before?”
It has two possible answers:
> “Definitely NOT in the set” — guaranteed correct.
> “Probably in the set” — correct with high probability, but not 100%.
That asymmetry is the whole trick. Bloom filters have no false negatives but can have false positives. In username checking, this means:
> If the filter says “available” → it’s available. ✅
> If the filter says “taken” → it’s probably taken (then a database lookup to confirm). ⚠️
This means you only hit the database for usernames that are likely collisions — which, in practice, is a tiny fraction of requests.
How It Works
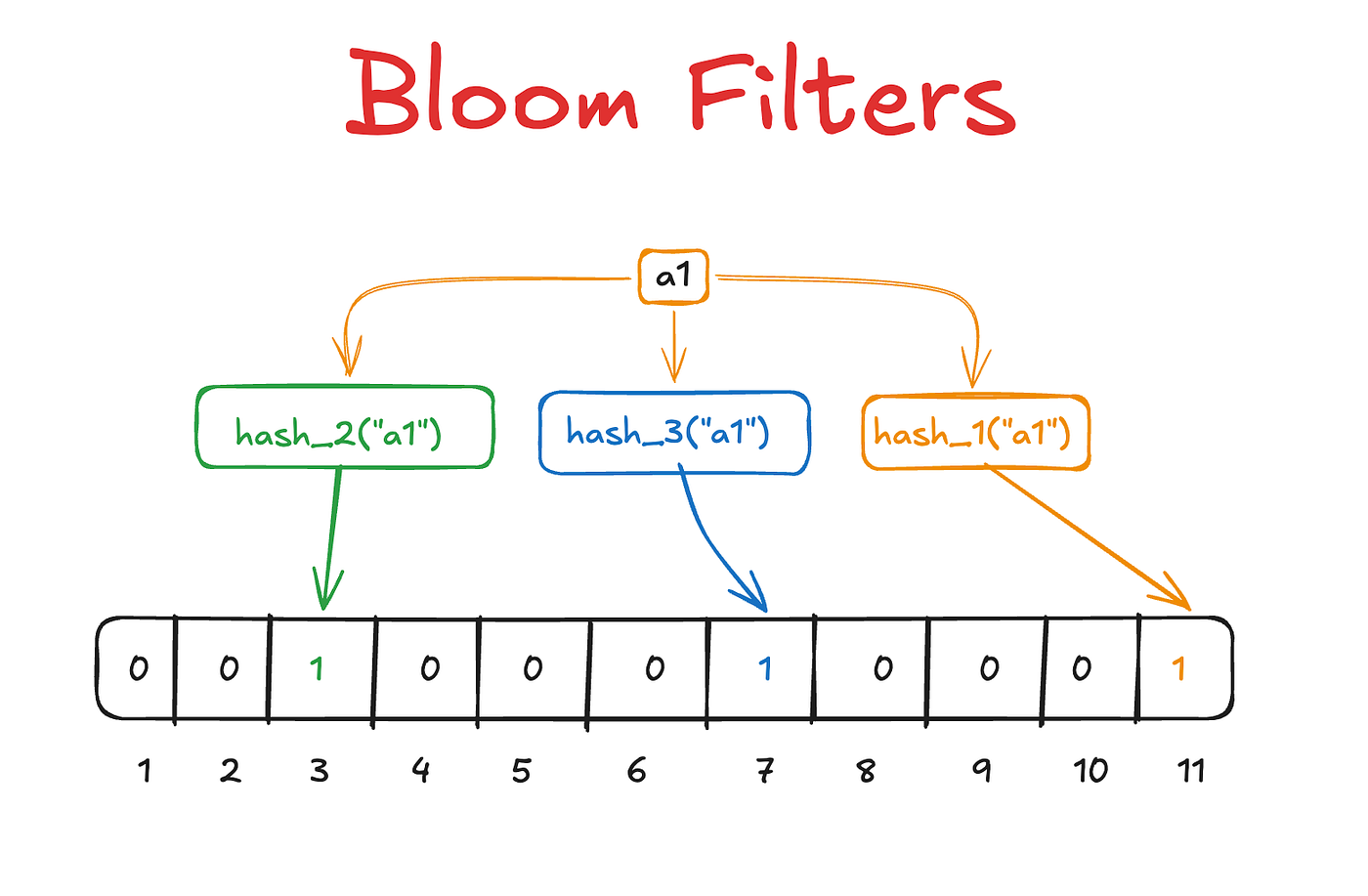
A Bloom filter is a bit array of size m, initially all zeros, combined with k independent hash functions.
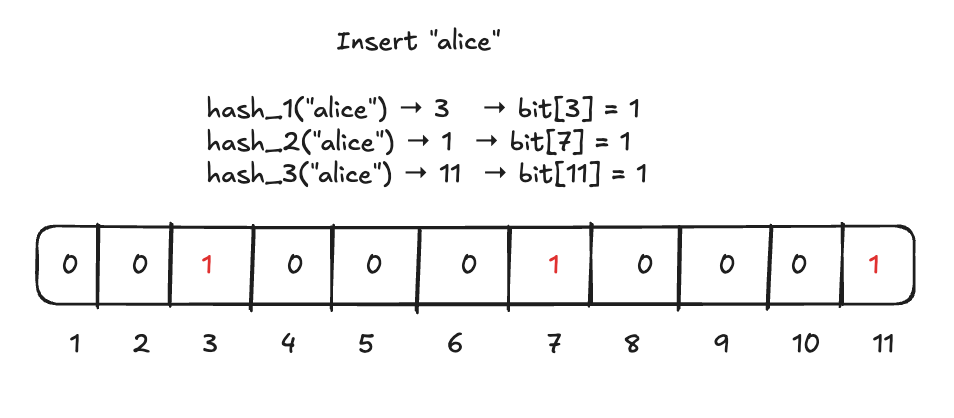
Insertion
To add an element, run it through all k hash functions. Each function produces an index. Flip those bits to 1. Assuming an m of size 12, and a k of size 3.
Lookup
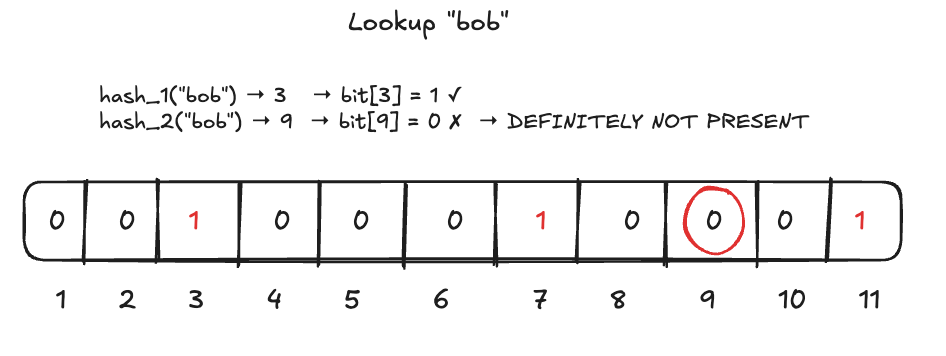
To check if an element exists, run it through the same k hash functions. If all resulting bits are 1, it's "probably present." If any bit is 0, it's definitely absent.
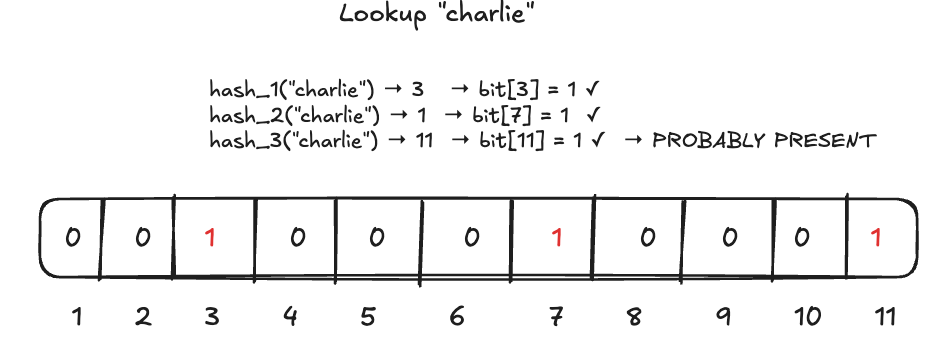
The false positive above? Bits 3, 7, and 11 were all set by “alice”, not “charlie” — but “charlie” got a hit anyway. This is the false positive rate in action.
Python Implementation
Let’s build one from scratch. We’ll use mmh3 (MurmurHash3) for fast, well-distributed hashing and bitarray for memory-efficient bit storage.
import mmh3
import math
import pickle
import re
from pathlib import Path
from typing import Union
from bitarray import bitarray
class BloomFilter:
"""
A space-efficient probabilistic data structure for membership testing.
Guarantees no false negatives. May produce false positives at a
configurable rate.
"""
def __init__(self, expected_items: int, false_positive_rate: float = 0.01):
"""
Args:
expected_items: How many items you expect to insert.
false_positive_rate: Acceptable false positive probability (0.0 - 1.0).
"""
self.expected_items = expected_items
self.fp_rate = false_positive_rate
# Calculate optimal bit array size
self.bit_count = self._optimal_bit_count(expected_items, false_positive_rate)
# Calculate optimal number of hash functions
self.hash_count = self._optimal_hash_count(self.bit_count, expected_items)
# Initialize the bit array (all zeros)
self.bits = bitarray(self.bit_count)
self.bits.setall(0)
self._inserted = 0
@staticmethod
def _optimal_bit_count(n: int, p: float) -> int:
"""m = -n * ln(p) / (ln(2))^2"""
return math.ceil(-n * math.log(p) / (math.log(2) ** 2))
@staticmethod
def _optimal_hash_count(m: int, n: int) -> int:
"""k = (m/n) * ln(2)"""
return max(1, round((m / n) * math.log(2)))
def _hash_positions(self, item: str) -> list[int]:
"""
Generate k bit positions for a given item using triple hashing.
Uses two base hashes to simulate k independent hash functions:
h_i(x) = (h1(x) + i * h2(x)) mod m
This avoids k full hash computations while maintaining quality distribution.
"""
h1 = mmh3.hash(item, seed=0, signed=False)
h2 = mmh3.hash(item, seed=1, signed=False)
h3 = mmh3.hash(item, seed=2, signed=False)
return [(h1 + i * h2 + i * h3) % self.bit_count for i in range(self.hash_count)]
def add(self, item: str) -> None:
"""Insert an item into the filter."""
for pos in self._hash_positions(item):
self.bits[pos] = 1
self._inserted += 1
def __contains__(self, item: str) -> bool:
"""
Test membership. Returns:
False → item is DEFINITELY not in the set.
True → item is PROBABLY in the set.
"""
return all(self.bits[pos] for pos in self._hash_positions(item))
@property
def current_false_positive_rate(self) -> float:
"""Estimate the current FP rate based on items inserted so far."""
if self._inserted == 0:
return 0.0
exponent = -self.hash_count * self._inserted / self.bit_count
return (1 - math.exp(exponent)) ** self.hash_count
@property
def fill_ratio(self) -> float:
"""Fraction of bits currently set to 1."""
return self.bits.count(1) / self.bit_count
def __repr__(self) -> str:
return (
f"BloomFilter("
f"bits={self.bit_count:,}, "
f"hashes={self.hash_count}, "
f"inserted={self._inserted:,}, "
f"fp_rate={self.current_false_positive_rate:.4%}"
f")"
)
Username Availability Checker
Now let’s wrap the Bloom filter in a realistic username-checking service.
import time
import random
import string
class UsernameChecker:
"""
Fast username availability check using a Bloom filter as the first gate.
Architecture:
Request → Bloom Filter → [probably taken] → DB lookup
→ [definitely free] → allow (no DB hit)
"""
def __init__(self, expected_users: int = 10_000_000, fp_rate: float = 0.001):
self.bloom = BloomFilter(expected_users, fp_rate)
self._registered: set[str] = set() # Simulates the real database
print(f"Initialized UsernameChecker")
print(f" Bit array size : {self.bloom.bit_count / 8 / 1024 / 1024:.2f} MB")
print(f" Hash functions : {self.bloom.hash_count}")
print(f" Target FP rate : {fp_rate:.2%}")
print()
def register(self, username: str) -> bool:
"""Register a new username. Returns True on success, False if taken."""
username = username.lower().strip()
if not self.is_available(username):
return False
# Claim the username
self._registered.add(username)
self.bloom.add(username)
return True
def is_available(self, username: str) -> bool:
"""
Check if a username is available.
Fast path: Bloom filter says definitely free → return True immediately.
Slow path: Bloom filter says probably taken → check actual DB.
"""
username = username.lower().strip()
# Fast path — no DB hit needed
if username not in self.bloom:
return True
# Slow path — verify against real data (could be a DB query)
return username not in self._registered
def stats(self) -> dict:
return {
"registered_users": len(self._registered),
"bloom_fill_ratio": f"{self.bloom.fill_ratio:.2%}",
"estimated_fp_rate": f"{self.bloom.current_false_positive_rate:.4%}",
}
See It in Action
Rather than walking through a wall of benchmark code, I’ve put together a live demo where you can register usernames, trigger false positives, and watch the bit array fill up in real time:
Try the live demo at https://bloom-filter.hanif.one/
Try registering a few names, then check one you haven’t registered — occasionally you’ll catch a false positive in the wild.
Watch the walkthrough: https://www.youtube.com/watch?v=KKIZsD4GcZ0
Limitations & Caveats
You can’t delete items. Setting a bit to 0 would invalidate other elements that share that bit. If you need deletion, look into Counting Bloom Filters or Cuckoo Filters.
The filter can’t tell you which items are present. It’s a membership oracle, not a dictionary.
False positives increase over time. Monitor fill_ratio. Keep it under ~40–50% for reliable performance.
Not a security primitive. An adversary who knows your hash seeds can craft inputs that always collide. Randomize seeds at startup and keep them secret if this matters.
Wrapping Up
Bloom filters are one of those data structures that feel like a cheat code once you internalize them. For the username-checking use case:
> A 500M user platform with 0.1% FP rate needs ~900 MB of RAM for the filter.
> That filter eliminates 99.9% of database round trips for available usernames.
> Lookups run in constant O(k) time — typically a handful of nanoseconds.
The probabilistic guarantee is the key insight: you’re not trying to be perfect, you’re trying to be fast. For the small fraction of false positives, you fall back to the database. The economics work out strongly in your favor.